The objective that I set to myself was to perform object detection directly from a video camera, so I made a prototype capable of reading from any video camera on the computer and capable of uploading any Youtube or disk video and making the analysis on the video.
Actually the prototype has been three different prototypes to test different scenarios (check the technical details at the end of the article if you are interested).
Object detection
The tests have gone quite well, it has helped me to see the state of technology at this time.Here you have the result of applying the recognition of objects on a video from New York that I found on Youtube. This example is treated with a Faster R-CNN Inception V2 COCO model. The original video is at 20.9 FPS and the result too.
In this other example you can see the prototype application running 5 times slower the same process on a street video of India with SSD_MobileNet_v1_COCO. The original video does not have good quality and the recognition scenario is a difficult one.If we compare it with the same video with Faster R-CNN model, we will see the differences in object detection.
Results
The results are really good. At this point my next objective becomes the detection of picking and counting objects. For this it will be necessary to enter in depth in the training on the model.
Technical details
For those of you who may are be interested in the technical details, here you have them. When not, leave the reading here to avoid irreversible neuronal damage…
Used technologies
I’m using:
OpenCV: I use it via the library OpenCvSharp-3 to make the video camera capture and to show the frames in the WinForm application as well as to draw in the frames to show the object detection and the estimation. In the same way I use this library to read from saved video file and to generate an output video file with the results.
TensorFlow: Obviously because using AI is one of the targets of this series to make the object detection, hand detection and create the models. I used TensorFlowSharp.
OpenCV DNN (Deep Neuronal Network): I test this extension to OpenCV just to review how well it handle object detection, but I discard this library, the speed and precision is clearly worst than tensor flow. I tried OpenCV DNN with YOLO (You Only Look Once) model.
Object detection
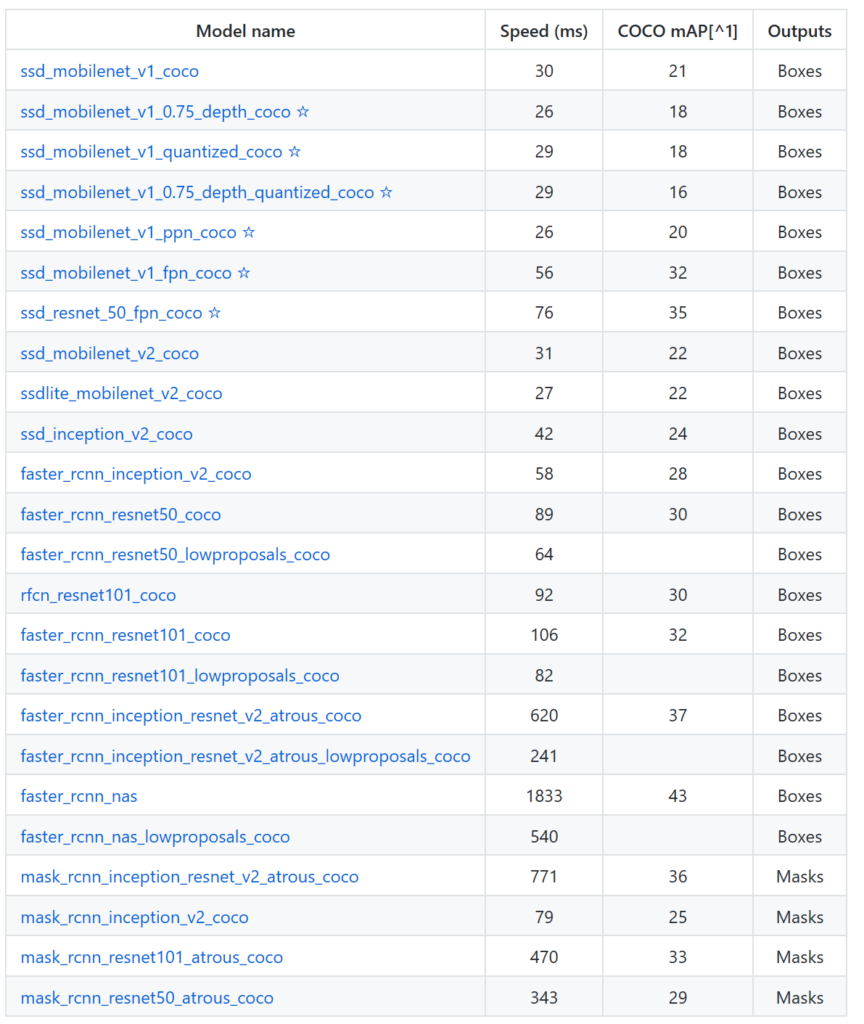
In order to do object detection correctly, I had to unlock a performance problem that was affecting my video processing. Basically the problems arrise with the cost of creating a Tensorflow session. If I create a session for each frame I get 7-15 seconds for each frame processing (which makes it anything less real time …). It took me a while to realize that the cost of executing each prediction on a newly created session was huge and that I had to reuse the session to process the entire video.To perform the recognition tests I used almost all models that are in the repository of TF models:
At the videos you will see only executions of SSD_MobileNet and Faster R-CNN that for my tests were the ones I liked the most in terms of results and response times. The first for its speed and the second for its precision (which is more what I look for thge use case that I am evaluating).