El objetivo que me marqué en este paso consistía en realizar detección de objetos directamente desde una cámara de vídeo, con lo cual realicé un prototipo capaz de leer de cualquier cámara de vídeo del ordenador o capaz de cargar un vídeo de Youtube o de disco y realizar el análisis sobre el vídeo.
Realmente el prototipo se ha convertido en tres diferentes prototipos para probar diferentes escenarios (revisar al final del artículo los detalles técnicos si estáis interesados).
Reconocimiento de objetos
Las pruebas han ido bastante bien, me ha servido para poder ver el estado de la tecnología en este momento.
Aquí tenéis el resultado de aplicar el reconocimiento de objetos sobre un vídeo de Nueva York que encontré en Youtube. Este ejemplo está tratado con un modelo Faster R-CNN Inception V2 COCO. El vídeo original está a 20,9 FPS y el resultado también.
Y en este otro ejemplo podéis ver la aplicación prototipo ejecutando 5 veces más lento el mismo proceso sobre un vídeo de calles de india con SSD_MobileNet_v1_COCO. El vídeo original no tiene muy buena calidad y el escenario de reconocimiento es complicado.
Si lo comparamos con el mismo vídeo con el modelo de Faster R-CNN veremos las diferencias de detección.
Resultados
Los resultados han sido muy motivadores. Llegados a este punto mi siguiente objetivo pasa a ser la detección del picking y el conteo de objetos. Para ello será preciso entrar en profundidad en el entrenamiento sobre el modelo.
Detalles Técnicos
Para aquellos que podáis tener interés por los detalles técnicos, aquí los tenéis. Al que no, que deje aquí la lectura para no sufrir daños irreversibles…
Tecnologías empleadas
A modo de resumen las tecnologías y alternativas empleadas han sido:
OpenCV: Lo he utilizado a través de la librería OpenCvSharp-3 y su función ha sido realizar la captura de vídeo, ayudar en la presentación del mismo en un formulario de la aplicación y para dibujar en el vídeo de salida las detecciones de objetos, así como su estimación. De igual forma me ha servido para preparar la aplicación para guardar en vídeo la salida del análisis para una posterior revisión.
TensorFlow: Lógicamente porque uno de los objetivos que me había marcado es utilizar AI para para realizar la detección de objetos, manos creación de modelos, etc. Lo he utilizado a través de la librería TensorFlowSharp.
OpenCV DNN (Deep Neuronal Network): He probado también esta extensión de OpenCV para ver su comportamiento con diferentes modelos. Básicamente para comparar su velocidad y precisión en detección de objetos respecto a TensorFlow. Aunque no he comparado peras con peras porque para probar OpenCV DNN utilice YOLO (You Only Look Once).
Detección de objetos
Para conseguir hacer correctamente la detección de objetos he tenido que desbloquear un problema de rendimiento que estaba afectando mi tratamiento de vídeo. Básicamente los problemas consistieron en el coste de crear una sesión de Tensorflow. Si para cada frame creaba una sesión se me iban 7-15 segundos por cada procesado de frame (lo cual lo convierte en cualquier cosa menos tiempo real…). Tardé un poco en darme cuenta que el coste de ejecución de cada predicción sobre una sesión recién creada era enorme y que tenía que reutilizar la sesión para el procesado de todo el vídeo.
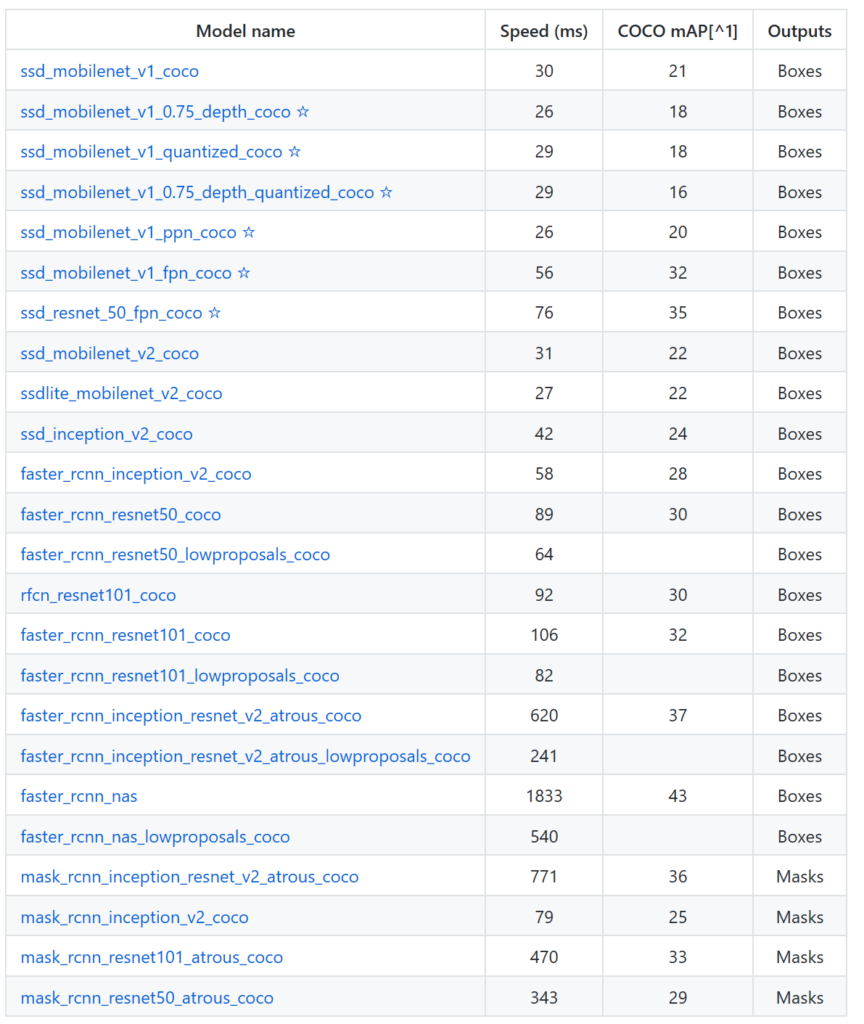
Para realizar las pruebas de reconocimiento utilicé la práctica totalidad de modelos que están en el repositorio de modelos de TF:
De los cuales a nivel de vídeo veréis solamente ejecuciones de SSD_MobileNet y Faster R-CNN que para mis pruebas fueron los que más me gustaron a nivel de resultados y tiempos de respuesta. El primero por su velocidad y el segundo por su precisión (que es más lo que busco para el caso de uso final que estoy evaluando).